> For the complete documentation index, see [llms.txt](https://liuzhenglaichn.gitbook.io/system-design/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://liuzhenglaichn.gitbook.io/system-design/news-feed/design-a-news-feed-system.md).
# Design a News Feed System
All the social media sites have some sort of news feed system, like those in Facebook, Twitter, Instagram, Quora, and Medium.
News feed is a list of posts with text, image, or video generated by other entities in the system tailored for you to read. It's constantly updating while other entities creating new posts.
## Requirement
### Functional requirement
1. News feed is generated using the posts from other entities in the system that the user followed or the user might be interested in.
2. Posts might have text, image and video.
3. The new posts generated by others should be appended to the news feed of the user.
### Non-functional requirement
1. **News feed generation**: should happen near-real-time. The latency seen by the end user should be just 1\~2 seconds.
2. **Appending new post**: After a new post is sent to the system, it shouldn't take more than 5 seconds to be able to show up in a news feed request.
## Capacity Estimation
> During the fourth quarter of 2019, *Facebook* reported almost 1.66 billion daily active users (*DAU*). Overall, daily active users accounted for 66 percent of monthly active users. With over 2.5 billion monthly active users, *Facebook* is the most popular social network worldwide.\
> \
>
The world population is just 7.8 billion as of March 2020. It means that 21% of world population are Facebook DAU and 32% are MAU. That's incredible.
To simplify computation, let's assume the system we are building have 1 billion DAU.
Assume on average a user follows 500 users or entities on Facebook. An entity can be a group or a page.
### Traffic Estimates
Assume on average one user fetches news feed 10 times per day. So it's `1e10` requests per day and about `116K` QPS.
### Storage Estimates
Assume on average we keep 500 posts of each user's news feed in memory for fast fetch, and each post is 1KB in size. So 500 KB per user, 500 TB for all DAUs, and 5000 machines if each of them has 100GB memory.
## System APIs
```
getNewsFeed(userId, options?)
```
userId (GUID): the id of the user who is fetching the news feed
The optional `options` parameter can contain the following fields:
afterPostId (GUID): fetch the news feed from after this post. If unspecified, fetch the newest posts.
count (number): the maximum number of posts returned for each request. If unspecified, some default maximum number is set by the backend.
excludeReplies (boolean): used to prevent the news feed from containing the replies.
The return values is a JSON containing a list of news feed items.
## Database Design
### Entities
1. User
2. Entity (page, group, etc): entityId, name, description, timestamp
3. Post: postId, title, text, authorId, timestamp
4. Media: mediaId, url, timestamp
### Relationships
1. Follower-Followee: A User can follow other Users or Entities. (m:n)
2. Author-Post: Users and Entities can generate Posts. For simplicity, assume only Users can generate Posts. (1:n; we can embed the authorId)
3. Post-Media: Each Post has some associated Medias. (1:n)
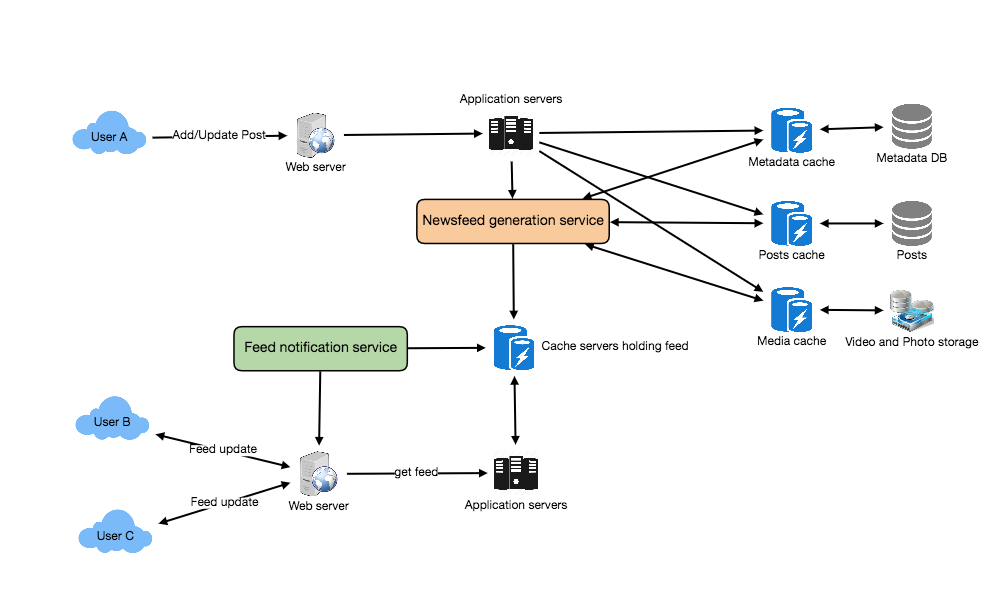
## High-level Design
### Workflows
#### Feed generation
When Alice ask for her news feed, the system will:
1. Get followees: retrieve the IDs of all the users/entities that Alice follows
2. Aggregate posts: retrieve latest, most pupular and relevant posts for those IDs.
3. Rank posts: rank the posts based on relevance and time.
4. Cache: cache the feeds generated and return the top 20 posts to Alice
5. Waterfall flow: When Alices reaches the end of those first 20 posts, another request is sent to fetch the next 20 posts.
#### Feed publishing (Live updates)
Assume Alice follows Bob, and Bod sends a new post. The system will need to update Alice's news feed:
1. Get followers: retrieve the IDs of Bob's followers
2. Add posts: Add the post Bob created to the news feed pool of those follower IDs.
3. Rank posts: rank the posts based on relevance and time.
4. Update Cache: update the ranked post into cache
5. Notify followers: let the follower know that there are new posts. (See [Server-to-client Communication](https://liuzhenglaichn.gitbook.io/systemdesign/server-to-client-communication))
### Components
1. Web servers: maintains connections with the users.
2. Application server: executes the workflows mentioned above.
3. Database and cache:
1. User/Entity: relationtional database
2. Post: relational database
3. Media (image/video): blob storge
4. Metadata: relational database
4. Dedicated services:
1. Feed generation
2. Feed notification
### Architecture
## Detailed Design
### Feed generation
#### Basic Implementation (Fan-out read)
```
SELECT FeedItemID FROM FeedItem WHERE SourceID in
(
SELECT EntityOrFriendID FROM UserFollow WHERE UserID =
)
ORDER BY CreationDate DESC
LIMIT 100
```
Issues of this implementation:
1. Super slow for users with a lot of friends/follows as we have to perform sorting/merging/ranking o a huge number of posts
2. We generate the timeline when a user loads their page. This could be quite slow and have high latency.
3. For live updates, each status update will result in feed updates for all followers. This could result in high backlogs in our Newsfeed Generation Service.
To improve the efficiency, we can pre-generate the timeline and store it in a memory.
#### Offline Generation (Fan-out write)
We can have dedicated servers that are continuously generating users' newsfeed and storing them in memory. Whenever a user requests for the news feed, we can simply serve it from the pre-generated, stored location.
**How many feed items should we store in memory for a user's feed?**
Adjust on usage pattern.
**Should we generate (and keep in memory) newsfeed for all users?**
For users that don't login frequently.
Simple solution: LRU based cache.
Smarter solution: learn the login pattern of users. What time? Which days of week?
### Feed publishing
The process of pushing a post to all the followers is called a **fanout**.
#### fanout read (pull)
When you request for news feed, you creates a read request to the system. With fanout read, the read request is fanned out to all your followees to read their posts.

Pro:
1. The cost of write operation is low.
2. Easier to do different aggregation strategies when reading the data.
Con:
1. The read operation is super costly for a user who has lots of followees.
2. new data can't be shown to the users until they pull.
3. If we periodically pull to fetch latest posts, it's hard to find the right pull cadence and most of the pull requests will result in an empty response, causing waste of resources.
This architecture is better for write-intensive application.
#### fanout write (push)
When you send a new post, you creates a write request to the system. With fanout write, the write request is fanned out to all your followers to update their newsfeed.

Pro:
1. The cost of read operation is low.
Con:
1. The write operation is super costly for a user who has millions of followers.
2. For inactive users or those rarely log in, pre-computing news feeds waste computing resources.
This architecture is better for read-intensive application. Take twitter as example, its `readRate >> writeRate`.
For systems have less latency requirement, we can use this approach as well. For example, WeChat Public Accounts do fanout write and all their followers get notified after some latency ranging from seconds to minutes.
#### Hybrid
Idea 1. For users who has lots of followers, stop fanout write for their new posts. Instead, the followers fanout read the celebrities' updates.
Idea 2. When users send new posts, limit the fanout write to only their online followers.
**How many feed items can we return to the client in each request?**
The backend should have some maximum limit. But it should be configurable by the client so that different client (mobile vs desktop) can have different limits.
**Should we always notify users if there are new posts available for their newsfeed?**
For mobile devices where data usage is relatively expensive, "Live Update" should be configurable by the client.
## Feed Ranking
Instead of simply ranking the feeds chronologically, today's ranking algorithms also try to ensure that posts of higher relevance are ranked higher.
* Select features that can determine the relevance of a feed item, e.g. number of likes, comments, shares, time of update, whether the post has images/videos, etc.
* Compute the score based on the features.
* Rank the posts using the score.
Set up metrics like user stickiness, retention, ads revenue, etc. to determine whether our ranking algorithm are good.
## Data Partitioning
### Sharding posts and metadata
As we have more users and posts, we need to scale our system by distributing our data onto multiple machines such that we can read/write efficiently.
### Sharding feed data
Since we only store a limited number of feeds in memory, we shouldn't distribute the feed data of one user onto multiple servers.
We can partition the user feed data based on userId. We hash the userId and map the hash to a cache server. We would need to use [consistent hashing](https://liuzhenglaichn.gitbook.io/systemdesign/consistent-hashing).
## Questions
1. is Facebook using SQL or NoSQL?\
2. How is the pagination implemented if the posts are not sorted chronologically?
3. Sharding data in designing twitter.